I wrote this blog post because I saw a woman throw a banana at Russell Brand. Bear with me on this one.
Yes, upon witnessing this act of fruit-based aggression I immediately related the incident to friends by typing a message about it. It struck me that the effort required to type the words ‘banana’ and ‘Brand’ on a modern Swype-style phone keyboard was incredibly annoying. My poor thumb scythed back and forth across the screen between the ‘A’s and ‘N’s for what seemed like hours. There must be a better way, I thought, to minimise the distance my thumb moves and thus delay the inevitable repetitive stress injury to my left hand.
In this post I’ll discuss optimising the layout of an English QWERTY keyboard in an effort to minimise the average distance a digit must travel to type a word. Let’s have a look.
The QWERTY keyboard
Let’s start by considering the standard English language keyboard layout, QWERTY:

When we talk about units of distance, in the above the horizontal and vertical offsets between letters are 1 unit. The distance required to type the word ‘QWERTY’ is then 5 units, or ‘TREE’ would be 2 units for example.
We can plot the distance between every pair of letters:
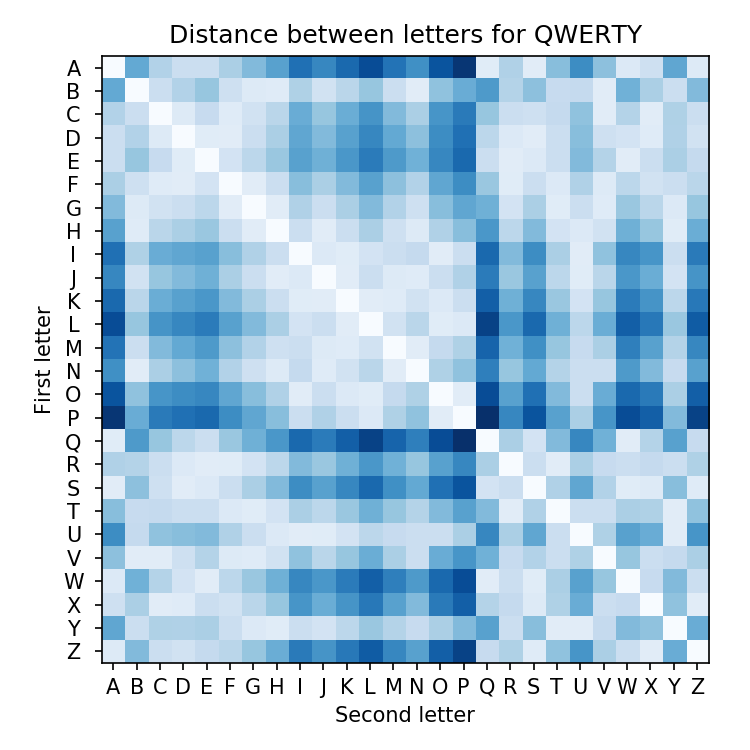
We can immediately see that the largest distances are between letters like Q and P. However this doesn’t matter very much because in English, those two letters don’t sit next to each other very often in words. Just as a sanity check, we can plot the average distance from each letter to all of the other letters:
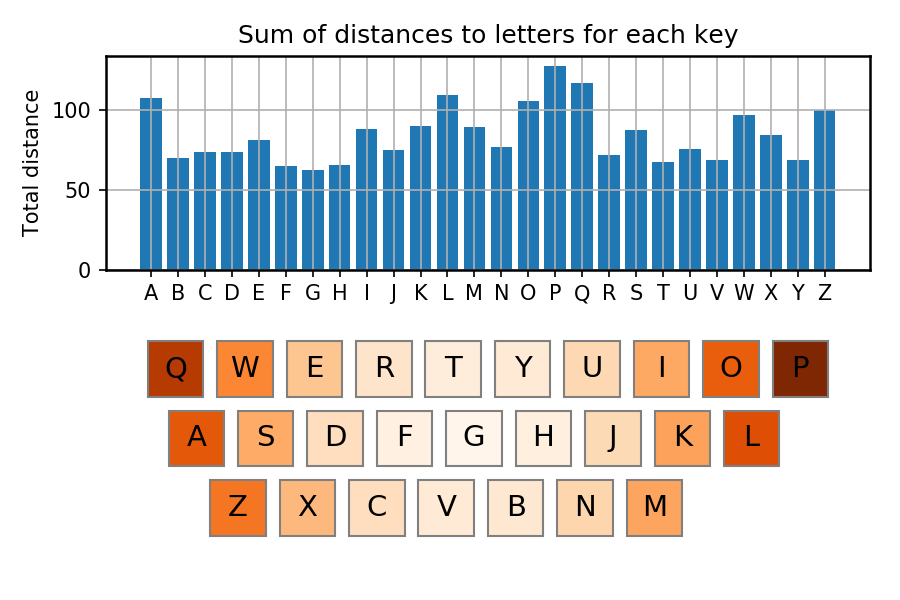
You might look at this and think that it is fine for Q to be right out at the edge of the keyboard, as it is used infrequently, but maybe it would be better if A were a bit closer to the centre, as it is used much more frequently.
To quantify this notion, I took the Reuters corpus from the NLTK library and tallied up the frequencies of transitioning between different letters in the English language:

Very popular pairings of letters appear to be ‘TH’, ‘HE’, ‘IN’ and ‘AN’. If I were to minimise average distances spent swiping around the keyboard, I might want to get these pairs of letters as close together as possible.
We can visualise which keys contribute most to word distances by taking the above transition frequencies into account, multiplying them by their distances on a QWERTY keyboard:
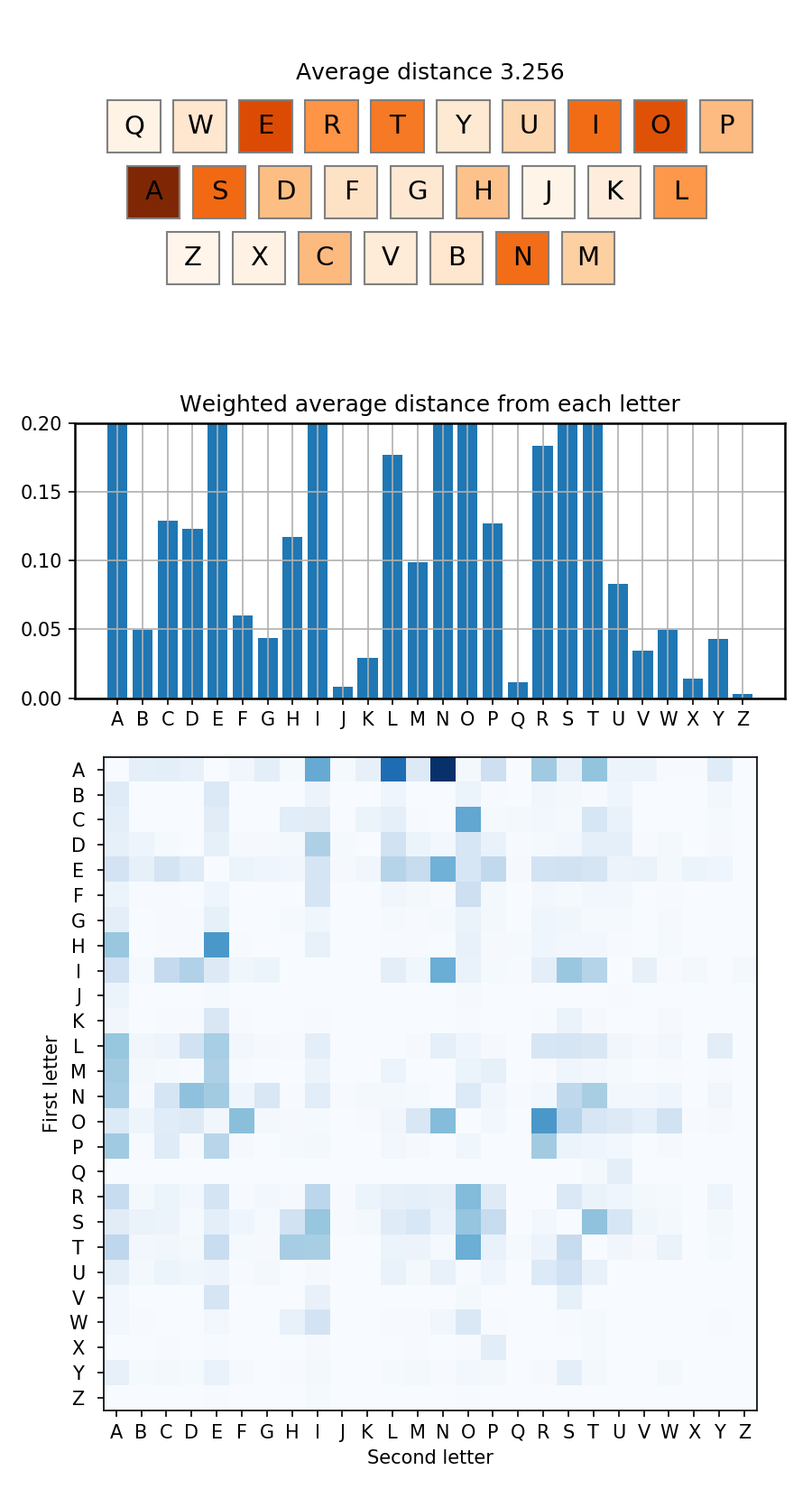
So here what really jumps out is that the ‘AN’ transition occupies a huge amount of distance when swyping the English language. The distance between A and N isn’t the largest on the keyboard, but because that letter pair appears so often the total distance is very large. We can also see that the total distances to and from the A key are the largest due to the fact it is a common letter and it sits at the edge of the keyboard.
Due to this, and other large distances, the average distance required per letter in the English language is approximately 3.2. On average then, the thumb skips over more than 2 keys between letters in the QWERTY layout.
Before we move on to optimising this sorry situation, let’s briefly go over how I am calculating these numbers.
Calculating average word distances
We have two important quantities here:
- A letter transition matrix counting the probability of transitioning between letters
. (Note here I don’t mean I and J, I am using
to index the letters alphabetically, so letter
is A,
is B etc.). This is only a function of the language, here English.
- A letter distance matrix
containing the physical distance between letters. This is a function of the keyboard layout, and is plotted above for QWERTY.
The total distance travelled from letter 
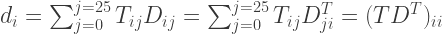
Note that because 
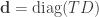
We then need to account for the occurrence probability of each letter in English 

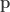
Finally then, the average distance for this keyboard, encoded in
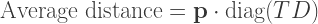
It is this quantity written at the top of the previous plot.
Optimisation procedure
There are a few constraints on possible keyboard layouts, namely
- There must be exactly 26 keys
- The key positions don’t change
- Each letter must appear exactly once
We are then searching over a permutation space. Each possible legal keyboard layout corresponds to a permutation applied equally to the rows and columns of
Unfortunately, there are 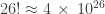
I therefore tried two different approximate search algorithms:
- Simulated annealing – repeatedly randomly swap two keys, and calculate the change in average distance
. Accept this change with probability
, where
and the the change is always accepted. To avoid being stuck in local minima, it is also possible to accept changes which increase the average distance, if
- Naive hill climbing – starting from a random initial configuration check all possible 26×26 letter swaps. Pick the one which delivers the most improvement, and repeat. If none are better, terminate.
Optimised keyboard layouts
Both techniques performed similarly, slightly surprisingly, finding many possible improved keyboard layouts. Neither is an exact approach, so there may be better layouts out there, but the best is one I dub NALMY/ZVDNALMY/GIERO:
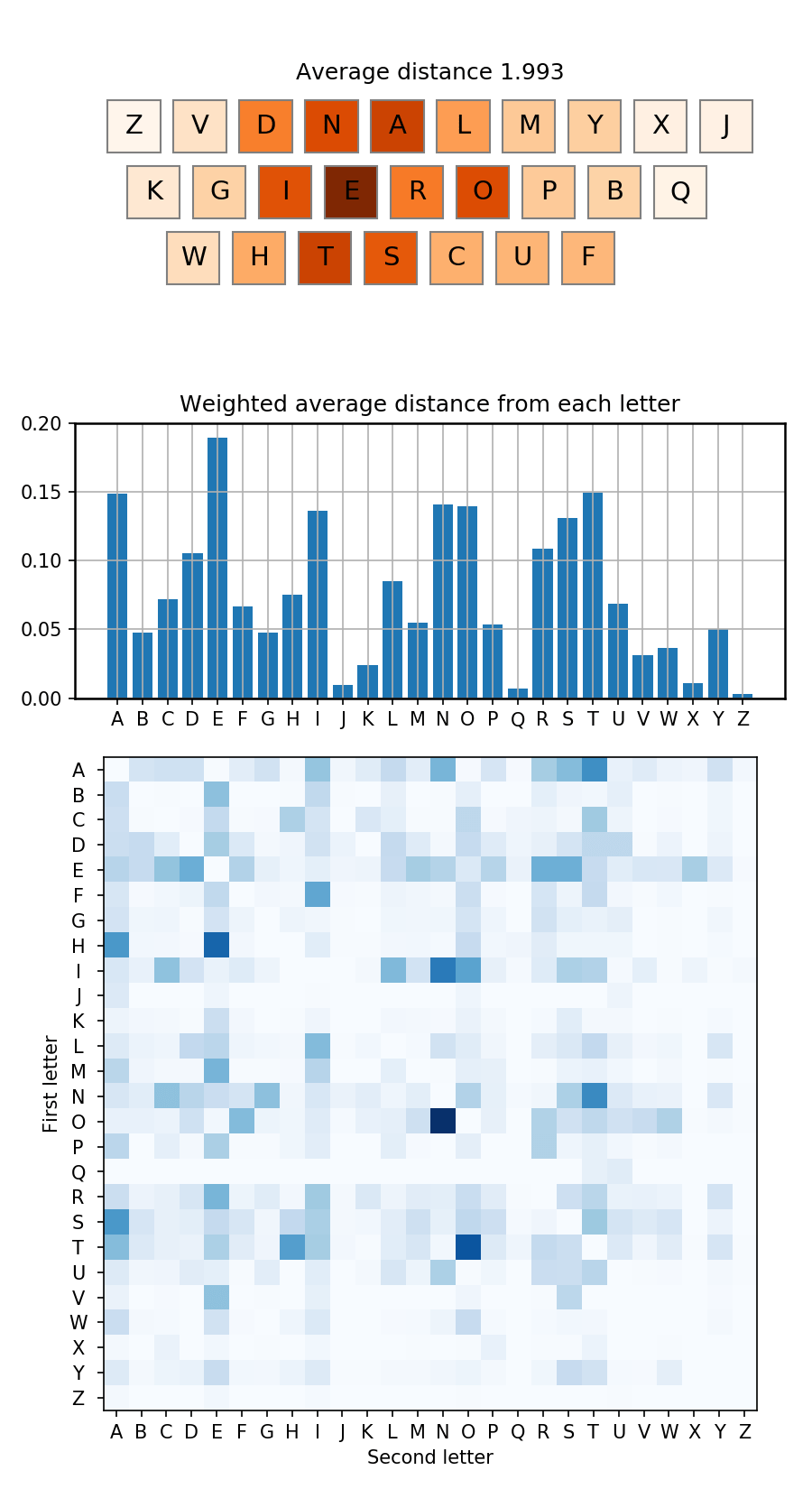
The average distance is down to below 2! 1.99324 to be exact. This is a 39% improvement on standard QWERTY, and means on average the thumb only has to skip over one key between letters rather than 2.
Here are a few other good configurations I found, which all have average distances below 2:
You can see a few commonalities between these approaches:
- The E key is uniformly placed in the centre of the keyboard for easy access
- A and N are always next to each other
- I and N are always next to each other
- R, S, T are always clustered together
- Z, Q, K, J, X are always relegated to the outer regions of the keyboard
Beyond these obvious tricks, it is also important to get some of the ‘second tier’ letters in just the right spots, including H, C, L and D. These letters usually want to be near particular letters, so their exact placement depends quite sensitively on the details of the central core of frequent letters.
Performance comparison
We can directly compare the efficacy of NALMY compared to QWERTY, for example by calculating the distances of every word in the English language for the two approaches. In the following, I have plotted the distance per letter for every word:
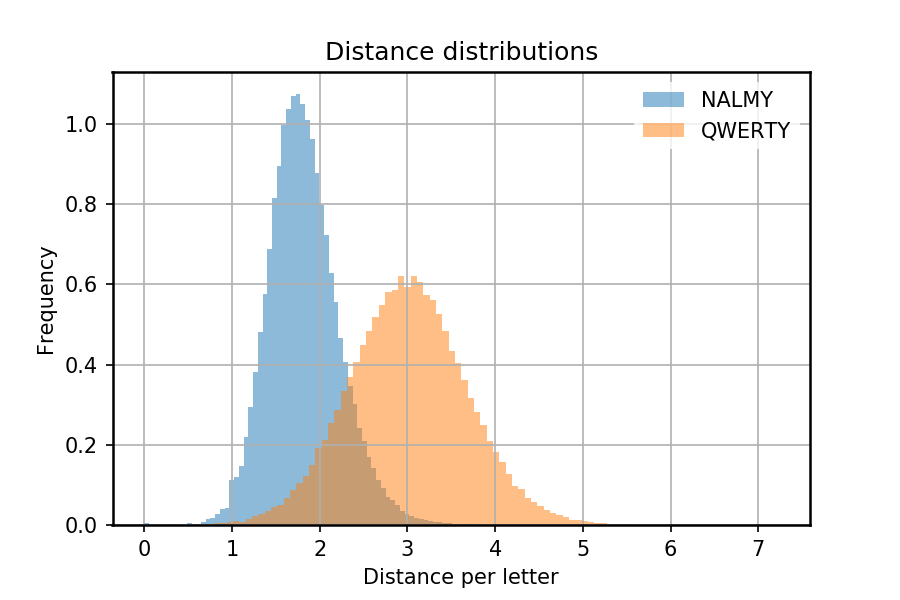
These are distributions over English words, and it is immediately clear that many words in NALMY require a distance of less than 2 units (keys) per letter, much better than QWERTY’s average of around 3.
The worst words to type in QWERTY, based on the distance required per letter, are palapalai, papal, jalapa
The worst words to type in NALMY, based on the distance required per letter, are syzygy, Uzbek, cozy
We can also plot these word distances as a joint distribution:
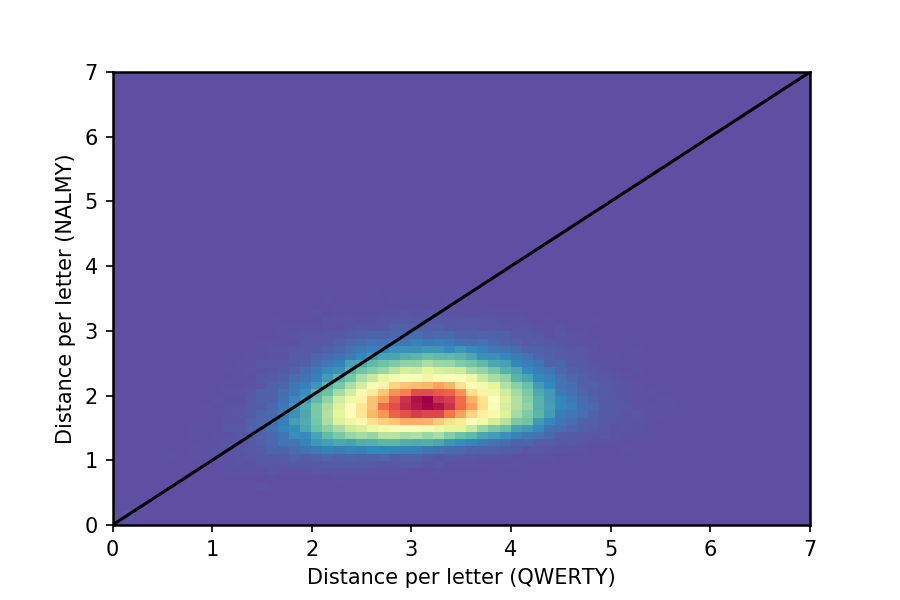
Any points above the line represent words which are made longer by NALMY, and below those which are made shorter. Obviously the vast majority are made shorter, but a few are worse off with this approach – the most obvious is the word ‘look’, for which QWERTY is uniquely optimised. (Also, hilariously, the word ‘pookoo’).
The most improved by NALMY are words like ‘Alan’, ‘land’ and ‘dial’, all of which previously necessitated ponderous swoops across the keyboard.
So… banana?
Getting down to the crux of the issue, was my irritation at the word ‘banana’ really justified? Well with the whole of the English language to benchmark against, I can confirm that:
- With QWERTY, ‘banana’ requires a distance of 4.6 per letter, putting it into the 99th percentile of all English words.
- With NALMY, ‘banana’ requires a distance of merely 1.3 per letter, dropping it to the 6th percentile.
Success!
As a final justification for my efforts, suppose that
- the English speaking world of around 500 million people switched to NALMY on a Swype-esque keyboard,
- each person typed around 1000 characters per day on their phone
- the distance per key is around 8mm,
then NALMY would save 5 million kilometres of thumb motion per day! Say each 8mm of thumb motion burns around 1 J of energy, then that’s 625 GJ of energy saved per day, or a decrease in average global human power expenditure of 10 MW.
Code
The shoddy code behind this post can be found on the repository for this blog as a Jupyter notebook, full of cryptic indexing and single-character variables used interchangeably:
https://github.com/jasmcole/Blog/tree/master/Swype%20Right
I very much welcome comments on more efficient approaches to this problem!

Another awesome blog – I was ready to swap all my keyboard binds until I realised how often I say cozy!
Would like to hear your insights on how things would look if we changed the keyboard layout – increasing / decreasing the number of rows for example. What about when splitting the standard keyboard into two down the middle (one part for each hand, or finger…) – do your methods result in similar the the other alternative well known layouts not designed for type writers…
I would still love YouTube versions of these blogs – good work!
LikeLike
Thanks! Changing the shape of the keyboard would help quite a lot I think, perhaps that’s an extension you can try 🙂 RE: YouTube, I think this is a face for radio (or wordpress)
LikeLike
The Dvorak keyboard was more efficient for the English language; developed in Oregon and used in their government offices. I was a Career and Technical Education teacher. I took a keyboarding class and was able to get to 55 wpm in a half hour lesson.
LikeLike
The most frustrating thing I find with Actual Swype is that a stroke from ‘I’ down to ‘N’ can be interpreted as any of ‘I’ (most often, most annoying), ‘IN’ or ‘ON’.
So I suggest some further work to look at the most common two- or three-letter words and ensure that any new layout sufficiently disambiguates between them. That too would save megawatts of thumb travel.
LikeLike
Great article! For a similar analysis see:
http://nbviewer.jupyter.org/url/norvig.com/ipython/Gesture%20Typing.ipynb
This also briefly goes into the question of how easily the keyboard confuses paths of different words.
LikeLike
Awesome! Thank you! I actually wanted to say that we don’t really want them as close as possible since it would make recognition almost impossible.
Thank you
LikeLike
You’re optimizing for one handed typing more than two handed typing. For two handed typing what matters by far the most is how often you have to alternate between hands, with distance within hand being secondary. Clustering vowels in the middle because they happen to be near to the other hand is useless for touch typists.
LikeLike
A few years ago I thought about a similar problem for an old (1800s) typewriter I found in a museum. It had a single dial used to select the next letter to print. By rearranging the order of the letters on the dial, you can significantly reduce the average “travel time”, for example putting Q after U is a good idea. It turns out that the arrangement on the actual typewriter was NOT optimal!
http://hardmath123.github.io/crown-typewriter.html
LikeLike