Here’s a post which combines my favourite bits of writing a blog – fairly mathematical, not too simple or difficult to implement, mostly based around pictures, not covered in my undergraduate education, and pretty damn useful in my job. Excited? You should be.
Inverse problems
It’s important to be regular, in many aspects of life, but most importantly of all when dealing with ill posed problems. I’ll come onto a specific example later, but for now consider the general matrix problem

where the information contained in 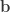
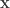
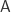
This is a matrix equation, so the answer is simple right? Just find the inverse of

Formally, this answer is correct and recovers 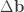


for some norm 


The scaling between the errors in the inputs and outputs is known as the condition number 

If
This is generically known as an ‘inverse problem’, where the ‘forward transform’ is known but the inverse transform problematic or impractical to calculate directly. Many problems can be translated into an inverse problem, a notable example being computed tomography which occupied a portion of my PhD.
Image deconvolution
Here let’s look at the simpler example of image deconvolution. When taking a picture, the ‘true image’ will be smeared across the image detector due to imperfections in the detector. This smearing can be modelled by a convolution

for some point-spread function (PSF) 
To cast this as an inverse problem, write the images and PSF in terms of pixels
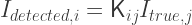
The PSF now takes the form of a matrix which relates how pixels 

Lets do this. Below I construct a Gaussian PSF, generate its matrix, and apply it to an image to make a blurred image. I then invert the matrix, and apply that to the blurred image to recover the initial ‘true’ image.

Worked perfectly! What’s the problem then? Let’s add a tiny amount of noise to the blurred image, just 1 count on average (out of an 8-bit gray value range 0-255)

The blurred image looks, by eye, to be identical to the previous figure. The recovered image is utterly corrupted though, to the point where no semblance of image structure is maintained. What happened?
If I calculate the condition number of the matrix 


The blue line marks what should be expected given the condition number of 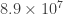
What is needed is a bit of regularisation.
Regularisation
The problem we are running into here is that, with some noise added, there can be many possible solutions for the recovered image. The large condition number of the matrix means that while 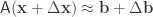

One solution is to penalise large values of
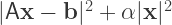
i.e. is close to a solution in a least-squares sense, but which also isn’t too large. The parameter 
Differentiating the above with respect to the components of

If 
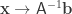


This relation can be interpreted as an iterative update, i.e.

In this case the iterates 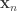
Regularised image deconvolution
Let’s finally see how well this technique works to de-blur images. Here Gaussian noise is added of magnitude 1:


If the noise magnitude is lower, the deconvolution is more successful:


If the noise magnitude is larger, the deconvolution isn’t very successful in improving the resolution, but it does lower the noise level:

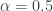
In practise, the parameter
If, rather than the square of the image, the total variation is penalised, the regularisation process encourages image uniformity (or ‘gradient sparsity’). This a technique widely used in computerised tomography, where it increases the quality of the 3D reconstruction without increasing the radiation dose to the patient.
Implementation
The code used in this post was written in Matlab, which deals well with large matrices. In particular the kernel matrix is large and sparse – for a 128×128 pixel image it is 16384×16384 and 99.5% sparse.
The scripts can be found here on Github. Keep the images small, even 128×128 takes a few tens of seconds to run.

See related video
Denoising, deconvolution and computed tomography using total variation regularization
LikeLike
Hi Michael, thanks for the video. I’ve been using PyHST2 recently (https://forge.epn-campus.eu/html/pyhst2/) which includes several convex optimisation algorithms for iterative TV denoising. It’s worked fairly well, but I’m looking also at MBIR methods. Do you have any experience with those?
LikeLike