Way back when I was analysing London house price data for the Summer Data Challenge, I made a histogram of the distances from a random point in London to the nearest tube station. I noted that it peaked around half a kilometre, but ignored the shape of the distribution itself. This is an unfortunate faux pas for the accomplished procrastinator, so let’s right that wrong with the help of some stochastic geometry.
The study of random spatial patterns is called stochastic geometry, and here we are most interested in a subfield which involves so-called point processes. This is the analysis of random distributions of points, as might be approximated by tube stations or, in the literature, mobile phone base stations.
Poisson point processes
A Poisson point process is one where the underlying distribution of points is Poisson. Given a mean density of points 



To simulate this, I take a unit square, split it into 400 small cells, and fill each cell with a random number of points which follow a Poisson distribution. The points are plotted below on the left. On the right I have sampled this distribution 100,000 times, measuring the number of points within a radius of 0.02 from a random point within the square. The agreement is good, suggesting that this is a good approximation to a Poisson point process.

The only problem with this method is that the total number of points 
Binomial point processes
In real life there will often be a fixed number of points to consider, so it would be nice to incorporate this fact. The solution is to switch to a binomial point process, where a fixed number 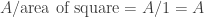
This is the standard binomial distribution, and so the number of points within an area
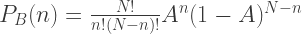
It’s simpler to generate a binomial point process as one just needs a list of N uniformly distributed x and y co-ordinates, and as plotted below the agreement with the expression above is again good.

Nearest points
This is all good so far, and we can generate the distributions we need. However the original problem was to investigate the distribution of the distances to the nearest point in an array of points. To work this out we need the probability that there is at least one point within a distance 

For the two cases above we have (for the unit square case where 


Finally, note that the probabilities here have been considered in a cumulative sense – we are calculating quantities within a certain radius. To get the probability density that the nearest point is actually at a certain radius requires the differentiation of the above
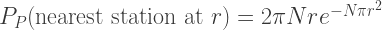
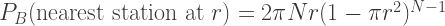
The astute amongst you will have noticed that for large
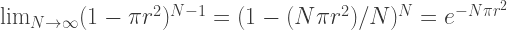
This is because the fractional variations in 
Here are histograms of the distance to the nearest point for a Poisson point process:

and a binomial point process:

In both cases the match is good, and so my maths isn’t completely terrible.
Fitting to the data
This is good, we understand how to model the distance to the nearest point in a couple of random distributions. How does this match up to the London tube station data?
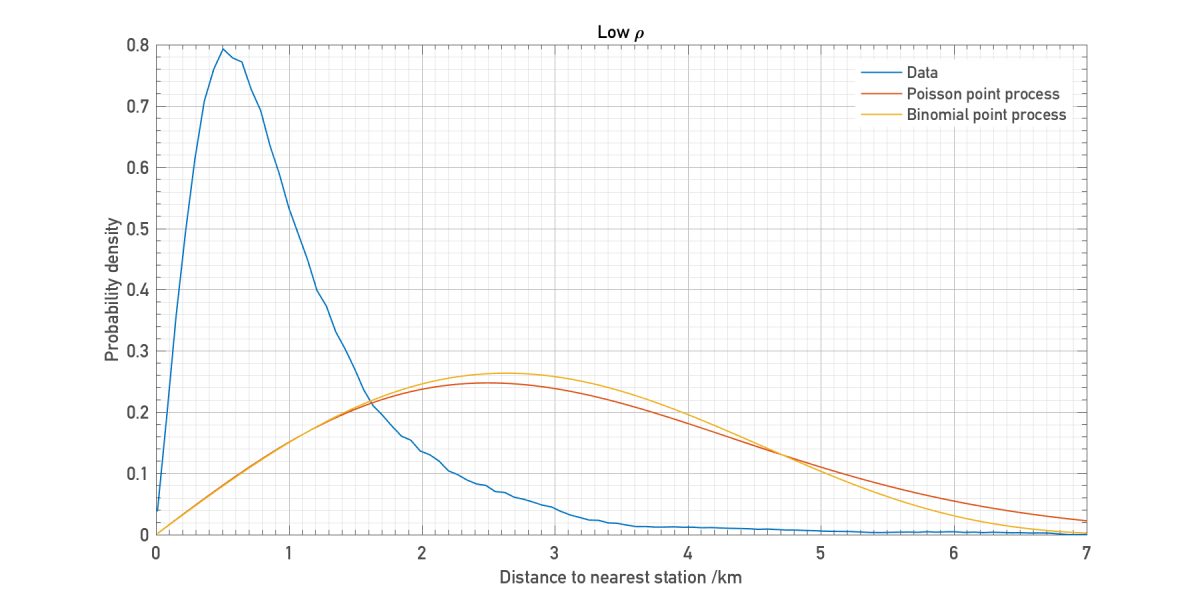
Let’s see how the distributions above compare for low density:
And high density:

It seems that we cannot reproduce the actual distribution with a simple model like this. In particular there is a long tail which is never matched by either the Poisson or binomial model. At the high densities required to get the peak in the right place, it becomes very unlikely that the nearest station can ever be very far away.
The key here is that London’s tube network isn’t homogenous like these point processes. It has a high density core surrounded by a low density halo, and so the model should be tweaked to account for this.
Let’s suppose that the station density varies as a function of distance. The number of stations within a radius

And so the Poisson point process is modified such that
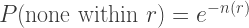
Churning through the same algebra as above, we get that the distance to the nearest station follows the distribution
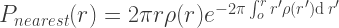
Now we have measured 

As plotted below the fit works well, matching the long tail of the actual distribution.
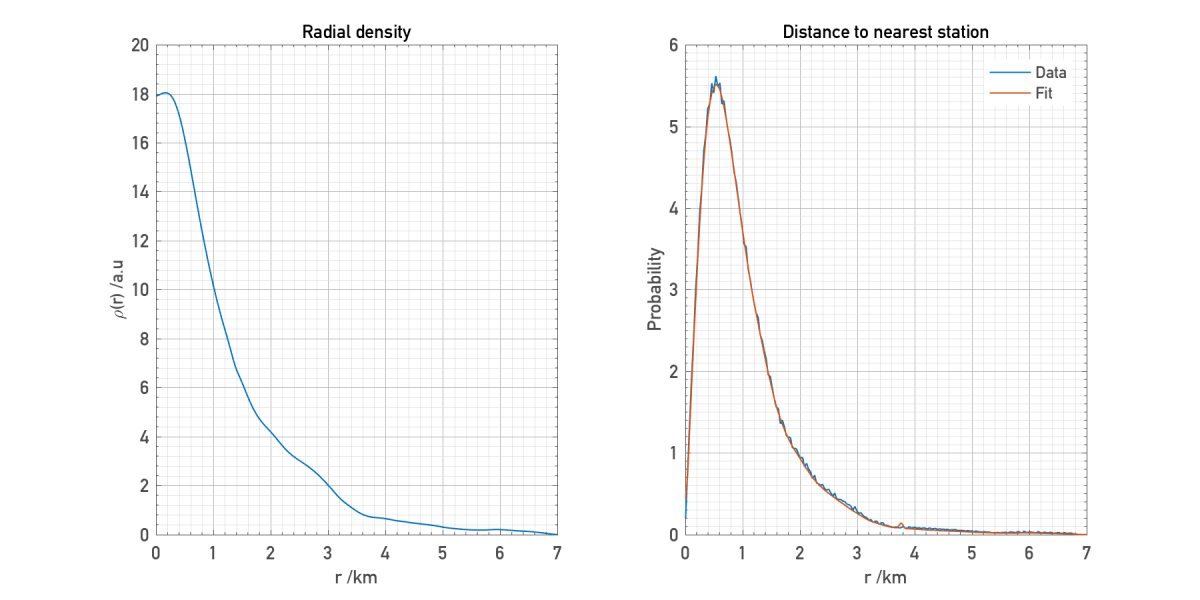
Though expected, it’s nice to see that the retrieved density matches the description outlined above. A dense core which quickly drops off after a few kilometres. Note that this is the average distribution as witnessed by many random observers plonked somewhere within London, so doesn’t correspond to the actual radial distribution of stations. However I find the fact that, in principle, it’s possible to calculate something like this from a simple observation of the distance to the nearest station pretty cool.
Code
You can access the scripts I used to make the plots in this post at the Github repository for my blog here.
Further reading
I learned most of the content in this post from a couple of papers, which you can find here:
Distance Distributions for Real Cellular Networks
Distance Distributions in Finite Uniformly Random Networks: Theory and Applications
