
A few years ago, a building in London known as the ‘walkie-talkie’ (actually 20 Fenchurch Street, but ever since the Gherkin it has been mandatory to give big expensive buildings extremely silly names. Can of Ham anyone?) started setting fire to shops and expensive cars. Let’s have a look at why that might be.
The obvious feature of this skyscraper (other than the almost complete incongruity with the surroundings) is that it is strongly curved inwards on its southern side:

Any inward curvature like this will act to focus the incoming light upon reflection. The fact that the tower curves over at the top also helps reflect the incoming light downwards onto the buildings it looms over.
Intriguingly, the designer of the walkie-talkie Rafael Viñoly was also responsible for a similar ‘death ray’ in Las Vegas. Perhaps he assumed the notoriously feeble British sunshine could never be focussed to high enough intensities to ever cause damage?
I’ll chronicle here my attempt to model this situation, inspired by this paper from my alma mater. While the paper is thorough, follows best scientific practices, and uses proper solar irradiance profiles, the visualisations left me wanting more. Casting proper science aside, let’s right that wrong and dig in.
The building
My initial thought was to model everything in Blender, and just let the rendering engine do all of the hard work of calculating light paths.
To draw up the building, I used the floorplans available here to get the shape correct, and smoothly interpolated the building shape between the floors.

I also used the surprisingly awesome export feature of OpenStreetMaps which includes building shapes and heights, then ran the export through the equally awesome OSM2World which spits out file formats readable by other 3D software – in this case, Blender.
A bit of modelling, importing, and rendering later, we get a lovely view of this chunk of the City, with some minimal external lighting:

Great (I thought). Let’s stick a sun lamp into the scene, and see which building it focusses on:

This was a bit disappointing – a faint splodge of white was not the death ray I was hoping for. Much fiddling with materials, lighting and renderer settings improved the render slightly, but it was still a struggle to generate anything which looked like it might melt a car.
Doing things properly
Leaving Blender behind then, I loaded the building model into python using trimesh, which also very helpfully does efficient ray-surface intersection calculations. Firing a load of rays at the building surface with direction 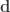


(where 

Here the incoming rays are spaced evenly in the plane normal to their direction, and so the density of rays at any point gives the light intensity. This is a simplified approximation, but will suffice for our purposes.
Tracing the paths of many thousands of rays, we can start to see how the reflected light propagates:

Here is actually the worst-case scenario – at an incident angle of around 16 degrees the light comes to a focus almost exactly on the ground. If we calculate the ray density on the ground, we can plot the ‘focal spot’ produced by the building:

Frighteningly, a significant portion of the entire incident light field is focussed to a small point, with the rest spread behind it longitudinally.
Varying the incident ray angle, we see how the light comes in and out of focus (we don’t show the incident rays for clarity):

The non-uniformities in the transverse direction are probably due to non-perfect smoothing of the building mesh – focal spots are very sensitive to departures from surfaces of constant second derivative.
If we plot the maximum intensity of the focal spot as a function of ray angle, there is a clear peak:
From this surprisingly cool site, we know that in summer time in London, the sun is at 16 degrees at 8AM in the morning and 6PM in the evening. Given these are peak commuting times, the unwary commuter could have ended up with a nasty surprise! Indeed, the paper linked above concludes that sun intensities may have been boosted by a factor of up to 16 times.
Fortunately, shortly after London started melting the developers applied some protective covers to the southern face of the building. This is much safer, and the right thing to do, but has the unfortunate side effect of completely ruining my chances of dropping the words ‘death-ray’ into casual conversation. Guess we’ll just have to wait for Rafael’s next great project.







{kind=link}