Let’s get pedagogical. Often when analysing a system, it is useful to break a component down into pieces, and figure out which are the important ones (if any). There are many techniques for this, here I’ll look at one called ‘singular value decomposition’ in the context of image compression.
Let’s start with the usual dry explanation of singular value decomposition (SVD). For any 


where 
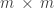



Writing this in index notation, we have

and letting the diagonal elements of 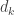

or in another way and reintroducing the suppressed summation sign,
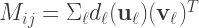
where 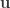
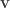
What is interesting is the way I’ve intentionally written the final step of the decomposition – to construct 
Let’s illustrate this with an example – image compression. Take the following grayscale image, famous in image processing circles:

This is a 2D array of numbers, or in other words, a matrix. We can therefore compute the SVD of this image, and reconstruct it from successively larger numbers of vectors
The following images and animation show how adding more vectors to this sum makes a gradually more faithful representation of the original matrix (image). In this case there are 512

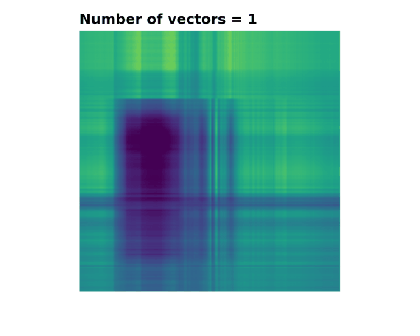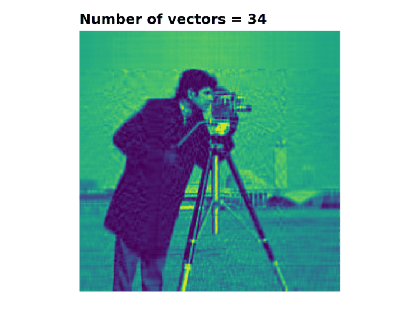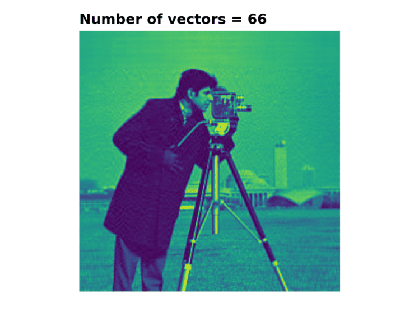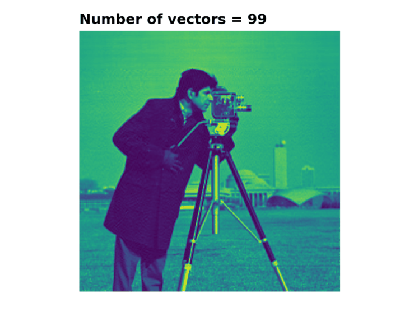
Hopefully you now understand both outer products and SVD a lot better. The top-left image in particular illustrates the outer product well: take some vectors along the left and top of the image, smear them across and down respectively, and multiply them together. This forms a 2D image from a pair of 1D vectors.
Features which are strongly horizontal or vertical are recreated the quickest, including the horizon and the tower in the background.
To understand how the accuracy improves as the reconstruction process proceeds, the next plot shows how the ‘amplitude’ (
 I’ve marked a few points to discuss how the scaling varies. The orange point shows that the ‘low’ order (small
I’ve marked a few points to discuss how the scaling varies. The orange point shows that the ‘low’ order (small 
After the green point a large portion of the image is accounted for, and by the red point the weighting factors are so small there’s almost no point having them.
If we look at the vectors themselves, we can see below that low-
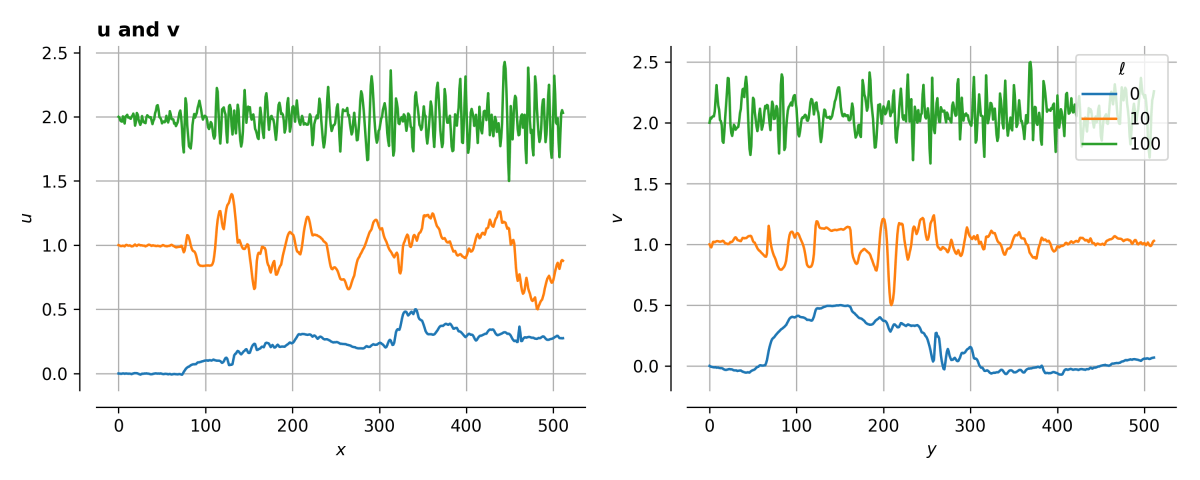
This means that the general structure of the image is encoded in the low-
One way to characterise the performance of any compression method is to see how the error in the reconstructed image varies with the image size.
Here, the image size 


where 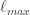

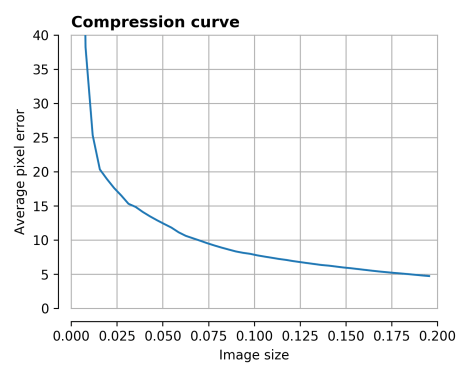
We see that for 

One thing you might notice is that for this image, different areas will have different compression curves. Parts of the sky are very uniform, and so will be well approximated by a small number of vectors.
To test this, I also tried halving the image a number of times 
The overall size of the image then becomes

i.e. the individual vectors have shrunk, but there are more of them in the overall image.
The following set of images show reconstructions for increasing

You can probably tell that the top-right quadrant of the image is constructed well very quickly, compared to the detail in the legs of the tripod. The compression curves are plotted below.
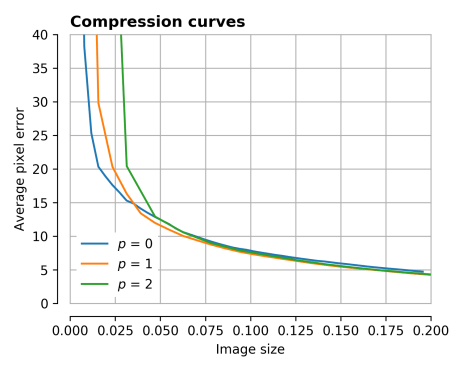
There is a very slight improvement – the orange and green curves dip slightly below the blue curve, but not much. We’re getting perhaps 10% improvement in either image size at a fixed pixel error, or pixel error at a fixed image size.
This is a bit disappointing, so let’s continue.
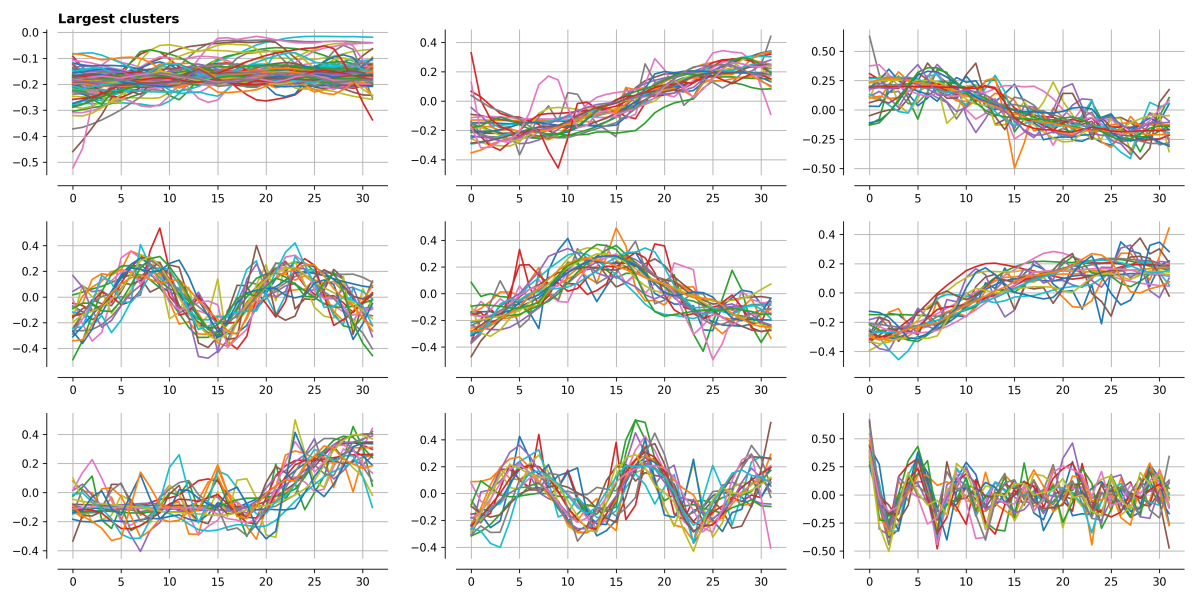
One thing that I noticed is that amongst the sub-images, several of the vectors computed for different SVDs looked quite similar. My idea was then to see if there were any ‘characteristic’ vectors which could be re-used across different sub-images, thereby saving the storage space of lots of similar vectors.
I used a method called k-means clustering here, but many algorithms exist, possibly with better performance.
Below I’ve plotted the 9 largest clusters, and it is clear that many vectors have similar forms – roughly uniform, increasing to the right, increasing to the left, single humps, double humps… to those of you who have done any Fourier analysis this should all look very familiar!
Finally, lets look at the performance of clustering compared to ‘simple’ SVD. The following plot is complicated, and shows several things:
- The compression curve of simple SVD – plotted as open circles
- For each
pair, there is a line for the cluster model, along which the number of clusters increases. As the number of clusters reaches
- Confusingly, in this plot I’ve called
, and I’ve called


This time there are some significant performance improvements at the lower image quality settings – a 6-fold savings in image size in some cases – see the following comparisons.

Admittedly these images don’t look great compared to the original image, but they do demonstrate the conceptual point that it is possible to find repeated or irrelevant information and remove it – essentially the basis of all compression techniques.
I think this is quite nice, and there are a few further avenues for improvement. For example,
- Different clustering algorithms
- Different
- Optimising the clustering
- Picking sparse representations of vectors, or sparse representations of differences from clustered vectors
- …
I’m sure this is all covered in various image compression formats somewhere (usually a generous commenter will tell me this kind of thing), and I know that JPEG in particular uses a discrete wavelet transform for example, but it’s always fun to try and have a go by oneself!
